Joel P. Schroeder
Course Description:
CS 145 - Introduction to Object-Oriented Programming Using Java
A general introduction to computer data representation, programming, and the design of computer software. Object-oriented design and implementation techniques and concepts are introduced.
Program 3: Webcrawler
A web crawler (a.k.a. robot or spider) is a program that automatically traverses the Web's hypertext structure by retrieving a document, recursively retrieving all documents that are referenced. Web crawlers can be used for a number of purposes, including indexing (i.e. google, yahoo, etc), HTML validation, link validation, “what’s new” monitoring, and mirroring. For this assignment, you will be building a basic web crawler that performs link validation (i.e. looking for broken links).
Program Structure
All your code must go in a class called WebCrawler. This class must contain the following functions. Note that you may not change these functions in any way.
public static void main(String[ ] args)
public static URL getStartingURLFromUser( )
public static String htmlReader(URL webURL)
public static ArrayList<String> linkParser(String htmlContents)
public static boolean isBrokenLink(URL baseURL, String theHREF)
public static void displayBrokenLinkReport(ArrayList<ArrayList<String>>brokenLinks)
//This web crawler was written by Joel Schroeder. 11/18/2010
Illustrated below are a few screen shots of this program.
package edu.uwec.cs.schroejp.webcrawler;
//http://www.cs.uwec.edu/~stevende/cs145testpages/default.htm
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import javax.swing.JOptionPane;
public class WebCrawler {
ArrayList<String> pagesVisited;
ArrayList<String> pagesToVisit;
public static URL getStartingURLFromUser() {
// This method gets the URL from user.
// Initializes the URL string.
URL startingURL = null;
// String startingString = "http://www.cs.uwec.edu/~stevende/cs145testpages/default.htm";
String startingString = JOptionPane.showInputDialog(null, "Enter a valid URL:");
startingString.toLowerCase();
// catches errors in URL.
try {
startingURL = new URL(startingString);
} catch (MalformedURLException e) {
System.out.println("Bad URL");
System.exit(0);
}
return startingURL;
}
public static String htmlReader(URL webURL) {
// Initializes the strings.
String htmlContent = null;
// Reading the file.
// This try/catch block reads in a file with a reader and creates a
// continuous string.
try {
URLConnection con = webURL.openConnection();
InputStream is = con.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String line = br.readLine();
while (line != null) {
htmlContent = htmlContent + line + " ";
line = br.readLine();
}
br.close();
} catch (MalformedURLException e) {
System.out.println("Bad URL");
System.exit(0);
} catch (FileNotFoundException e) {
e.printStackTrace();
System.out.println("File not found.");
} catch (IOException e) {
e.printStackTrace();
System.out.println("after try/catch");
}
return htmlContent;
}
public static ArrayList<String> linkParser(String htmlContents) {
// Initializes the strings, boolean, variables and arraylist.
ArrayList<String> listOfLinks = new ArrayList<String>();
int i = 0;
int k = 0;
boolean search = true;
String URL = "";
// This loop creates an array list of URL's.
while (search == true) {
i = htmlContents.indexOf("HREF=", k) + 6;
k = htmlContents.indexOf("\">", i);
URL = htmlContents.substring(i, k);
listOfLinks.add(URL);
if (i == htmlContents.lastIndexOf("HREF=") + 6) {
search = false;
}
}
return listOfLinks;
// System.out.println(htmlContents);
}
public static boolean isBrokenLink(URL currentURL, String theHREF) {
// Initializes the strings, boolean, variables and arraylist.
Boolean isbroken = false;
try {
URL baseURL = new URL(currentURL, theHREF);
URLConnection con = currentURL.openConnection();
HttpURLConnection httpProtocol = (HttpURLConnection) con;
httpProtocol.getResponseCode();
int httpPro = httpProtocol.getResponseCode();
if (httpPro != 200) {
isbroken = true;
}
} catch (MalformedURLException e) {
isbroken = true;
System.out.println("Bad URL1");
} catch (FileNotFoundException e) {
isbroken = true;
e.printStackTrace();
System.out.println("File not found.");
} catch (IOException e) {
isbroken = true;
e.printStackTrace();
System.out.println("after try/catch");
}
return isbroken;
}
public static void displayBrokenLinkReport(
ArrayList<ArrayList<String>> brokenLinks) {
System.out.println("Broken Link Report: \n");
for (int j = 0; j < brokenLinks.size(); j++) {
for (int i = 0; i < brokenLinks.get(j).size(); i++) {
if (j == 0) {
System.out.println("Page " + brokenLinks.get(j).get(i));
} else {
System.out.println("Broken link "
+ brokenLinks.get(j).get(i));
}
}
}
}
public static void main(String[] args) {
// Initializes the arraylists and the array<arraylist
ArrayList<URL> pagesVisited = new ArrayList<URL>();
ArrayList<URL> pagesToVisit = new ArrayList<URL>();
ArrayList<String> listOfLinks = null;
ArrayList<String> badLinks = null;
ArrayList<ArrayList<String>> brokenLinks = new ArrayList<ArrayList<String>>();
int i = 0;
// calls the getStartingURLFromUser method which returns the string.
pagesToVisit.add(getStartingURLFromUser());
while (!pagesToVisit.isEmpty()) {
URL baseURL = pagesToVisit.get(0);
pagesVisited.add(baseURL);
pagesToVisit.remove(0);
// calls the htmlReader method which returns the string.
String htmlContent = htmlReader(baseURL);
// calls the linkParser method which returns the array list.
listOfLinks = linkParser(htmlContent);
// calls the isBrokenLink method which returns the string.
for (i = 0; i <= (listOfLinks.size()); i++) {
boolean isBL = isBrokenLink(baseURL, listOfLinks.get(i));
System.out.println(listOfLinks.get(i) + "a");
if (isBL) {
System.out.println(listOfLinks.get(i));
badLinks.add(listOfLinks.get(i));
} else {
// catches errors in URL.
URL nextURL = null;
try {
nextURL = new URL(baseURL, istOfLinks.get(i));
if (!pagesVisited.contains(nextURL)) {
pagesToVisit.add(nextURL);
}
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("Bad URL2");
}
}
}
brokenLinks.add(badLinks);
}
displayBrokenLinkReport(brokenLinks);
}
}
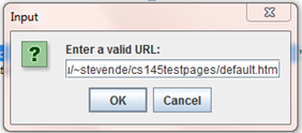
This input box allows a user to enter the website to be parsed.
Course Description:
CS 145 - Introduction to Object-Oriented Programming Using Java
A general introduction to computer data representation, programming, and the design of computer software. Object-oriented design and implementation techniques and concepts are introduced.
Program 3: Webcrawler
A web crawler (a.k.a. robot or spider) is a program that automatically traverses the Web's hypertext structure by retrieving a document, recursively retrieving all documents that are referenced. Web crawlers can be used for a number of purposes, including indexing (i.e. google, yahoo, etc), HTML validation, link validation, “what’s new” monitoring, and mirroring. For this assignment, you will be building a basic web crawler that performs link validation (i.e. looking for broken links).
Program Structure
All your code must go in a class called WebCrawler. This class must contain the following functions. Note that you may not change these functions in any way.
public static void main(String[ ] args)
public static URL getStartingURLFromUser( )
public static String htmlReader(URL webURL)
public static ArrayList<String> linkParser(String htmlContents)
public static boolean isBrokenLink(URL baseURL, String theHREF)
public static void displayBrokenLinkReport(ArrayList<ArrayList<String>>brokenLinks)
//This web crawler was written by Joel Schroeder. 11/18/2010
Illustrated below are a few screen shots of this program.
package edu.uwec.cs.schroejp.webcrawler;
//http://www.cs.uwec.edu/~stevende/cs145testpages/default.htm
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import javax.swing.JOptionPane;
public class WebCrawler {
ArrayList<String> pagesVisited;
ArrayList<String> pagesToVisit;
public static URL getStartingURLFromUser() {
// This method gets the URL from user.
// Initializes the URL string.
URL startingURL = null;
// String startingString = "http://www.cs.uwec.edu/~stevende/cs145testpages/default.htm";
String startingString = JOptionPane.showInputDialog(null, "Enter a valid URL:");
startingString.toLowerCase();
// catches errors in URL.
try {
startingURL = new URL(startingString);
} catch (MalformedURLException e) {
System.out.println("Bad URL");
System.exit(0);
}
return startingURL;
}
public static String htmlReader(URL webURL) {
// Initializes the strings.
String htmlContent = null;
// Reading the file.
// This try/catch block reads in a file with a reader and creates a
// continuous string.
try {
URLConnection con = webURL.openConnection();
InputStream is = con.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String line = br.readLine();
while (line != null) {
htmlContent = htmlContent + line + " ";
line = br.readLine();
}
br.close();
} catch (MalformedURLException e) {
System.out.println("Bad URL");
System.exit(0);
} catch (FileNotFoundException e) {
e.printStackTrace();
System.out.println("File not found.");
} catch (IOException e) {
e.printStackTrace();
System.out.println("after try/catch");
}
return htmlContent;
}
public static ArrayList<String> linkParser(String htmlContents) {
// Initializes the strings, boolean, variables and arraylist.
ArrayList<String> listOfLinks = new ArrayList<String>();
int i = 0;
int k = 0;
boolean search = true;
String URL = "";
// This loop creates an array list of URL's.
while (search == true) {
i = htmlContents.indexOf("HREF=", k) + 6;
k = htmlContents.indexOf("\">", i);
URL = htmlContents.substring(i, k);
listOfLinks.add(URL);
if (i == htmlContents.lastIndexOf("HREF=") + 6) {
search = false;
}
}
return listOfLinks;
// System.out.println(htmlContents);
}
public static boolean isBrokenLink(URL currentURL, String theHREF) {
// Initializes the strings, boolean, variables and arraylist.
Boolean isbroken = false;
try {
URL baseURL = new URL(currentURL, theHREF);
URLConnection con = currentURL.openConnection();
HttpURLConnection httpProtocol = (HttpURLConnection) con;
httpProtocol.getResponseCode();
int httpPro = httpProtocol.getResponseCode();
if (httpPro != 200) {
isbroken = true;
}
} catch (MalformedURLException e) {
isbroken = true;
System.out.println("Bad URL1");
} catch (FileNotFoundException e) {
isbroken = true;
e.printStackTrace();
System.out.println("File not found.");
} catch (IOException e) {
isbroken = true;
e.printStackTrace();
System.out.println("after try/catch");
}
return isbroken;
}
public static void displayBrokenLinkReport(
ArrayList<ArrayList<String>> brokenLinks) {
System.out.println("Broken Link Report: \n");
for (int j = 0; j < brokenLinks.size(); j++) {
for (int i = 0; i < brokenLinks.get(j).size(); i++) {
if (j == 0) {
System.out.println("Page " + brokenLinks.get(j).get(i));
} else {
System.out.println("Broken link "
+ brokenLinks.get(j).get(i));
}
}
}
}
public static void main(String[] args) {
// Initializes the arraylists and the array<arraylist
ArrayList<URL> pagesVisited = new ArrayList<URL>();
ArrayList<URL> pagesToVisit = new ArrayList<URL>();
ArrayList<String> listOfLinks = null;
ArrayList<String> badLinks = null;
ArrayList<ArrayList<String>> brokenLinks = new ArrayList<ArrayList<String>>();
int i = 0;
// calls the getStartingURLFromUser method which returns the string.
pagesToVisit.add(getStartingURLFromUser());
while (!pagesToVisit.isEmpty()) {
URL baseURL = pagesToVisit.get(0);
pagesVisited.add(baseURL);
pagesToVisit.remove(0);
// calls the htmlReader method which returns the string.
String htmlContent = htmlReader(baseURL);
// calls the linkParser method which returns the array list.
listOfLinks = linkParser(htmlContent);
// calls the isBrokenLink method which returns the string.
for (i = 0; i <= (listOfLinks.size()); i++) {
boolean isBL = isBrokenLink(baseURL, listOfLinks.get(i));
System.out.println(listOfLinks.get(i) + "a");
if (isBL) {
System.out.println(listOfLinks.get(i));
badLinks.add(listOfLinks.get(i));
} else {
// catches errors in URL.
URL nextURL = null;
try {
nextURL = new URL(baseURL, istOfLinks.get(i));
if (!pagesVisited.contains(nextURL)) {
pagesToVisit.add(nextURL);
}
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("Bad URL2");
}
}
}
brokenLinks.add(badLinks);
}
displayBrokenLinkReport(brokenLinks);
}
}
This input box allows a user to enter the website to be parsed.
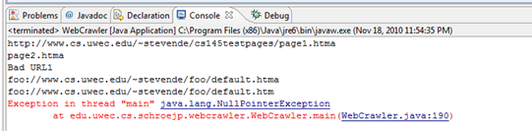
This screen shot illustrates the web addresses that have been parsed.